// For Apple Silicon curl -L https://github.com/tetherto/qvac-fabric/releases/download/v1.0/qvac-macos-apple-silicon-v1.0.zip -o qvac-macos.zip unzip qvac-macos.zip cd qvac-macos-apple-silicon-v1.0 # Download model mkdir -p models wget https://huggingface.co/Qwen/Qwen3-1.7B-GGUF/resolve/main/qwen3-1_7b-q8_0.gguf -O models/qwen3-1.7b-q8_0.gguf # Download dataset wget https://github.com/tetherto/qvac-rnd-fabric-llm-finetune/raw/main/evaluation/biomedical_qa/biomedical_qa.zip unzip biomedical_qa.zip # Quick test with email style transfer ./bin/llama-finetune-lora -m models/qwen3-1.7b-q8_0.gguf -f train.jsonl -c 512 -b 128 -ub 128 -ngl 999 --lora-rank 16 --lora-alpha 32 --num-epochs 3
Fabric LLM Finetuning
Our edge-first framework transforms any consumer device into a capable fine-tuning node. No central clouds, no massive data centers, no vendor dependency
From Android smartphones to high-end workstations, our unified system allows LoRA fine-tuning directly in the llama.cpp ecosystem so you can initialize, train, checkpoint and merge adapters locally for maximum privacy and resilience.
 Find it on Github
Find it on GithubTrain. Anywhere.
Whether it's Adreno, Mali or Apple, our novel dynamic tiling algorithm lets you train wherever you are. Fabric is the first to offer this previously unsupported capability.

Scalable across all platforms
Our solution provides universal compatibility across the entire desktop GPU ecosystem, including AMD, Intel, NVIDIA, and Apple architectures. By leveraging Vulkan, we ensure your sensitive datasets never leave your control while maintaining total operational resilience.

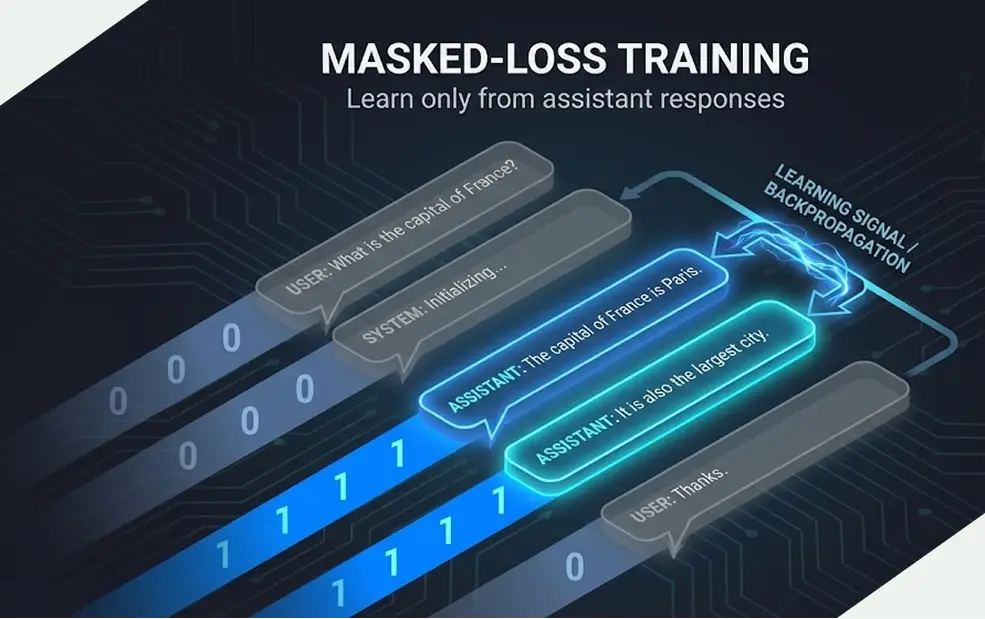
Masked-loss training
We implemented masked-loss training, where a mask is applied to train only on assistant tokens. This ensures that user and system messages influence the context but not the loss and that the same tokenization and masking logic are used consistently during both dataset creation and loss computation.
Start by using our pre-trained adapters
To accelerate development and innovation, we have publicly released Fine-tuned LoRA adapters trained using Fabric. These adapters work on any GPU and are available for Qwen3 and Gemma3 models.